check-pnr-status, The easiest way to track your PNR numbers
19 Sep 2015 cli · linux · nodejsMid-term exams are almost over. One more paper to go, and there’s enough time to study for that. So, I worked on the project that I have been working on for about a week now.
My ultimate goal for building this CLI module was to basically ensure that I didn’t have to visit the IRCTC website whenever I wanted to check the status of all the tickets that I have booked. (After the ARP for booking tickets was extended to four months, I can book tickets for February 2016 today!)
Thus, a lot of tickets, and a really really slow website. But there’s one thing that’s not slow, or atleast not as slow as the website itself. The API that the website consumes. So, I went out onto the open internet and started searching for a wrapper written in any language, but one that consumed the IRCTC API (the PNR status part, at the very least), so that I could model my code as per the requests in that wrapper, and hence have access to the API. Searching was hard and took a significant bit of time.
Unsurprisingly, as this was not a programming issue, but one that is India-centric, I didn’t find anything on Stack Overflow. What really helped me though was this Quora question.
Going through each answer in turn, I finally ended up at this GitHub repository by @salilpa.
I found out the requests I had to make to get the required data. I didn’t go into the
detailed code of the repository, but I got the request I wanted, and yay! I was ready to parse
the information out of the complex and completely unstructured HTML that IRCTC pages
are always composed of! (There were 5 nested tables with a huge amount of tr and td elements
inside each other that made looking at the markup not even an option.)
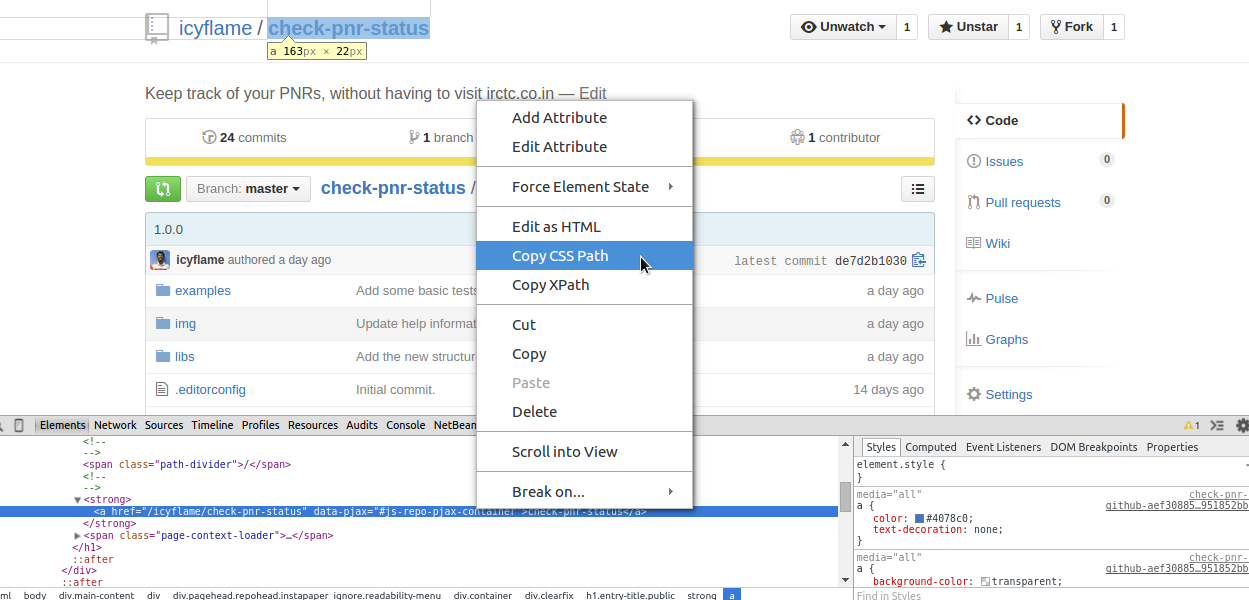
Here, Chrome Dev Tools helped out, and saved the day! I highlighted the element I wanted
and used the Copy CSS Path functionality, which worked perfectly!
Now, I had to parse the information I wanted out of the HTML, and I all I had were CSS selectors. I needed something like jQuery, that would build the DOM and then, allow me to select the text / HTML of the required element. Suffice it to say that it was not as easy as it sounds, and certainly not as easy as in the browser (where the DOM is always available).
I started out with cheerio, as almost everyone loathed
jsdom and had shifted from jsdom to cheerio. I started working with it,
and there was some weird problem. It was working with one of the selectors which had an
ID followed by three other tr:nth-child blocks. But it wasn’t working with any of the other
three selectors. Around 45 minutes of debugging led me to a one-liner StackOverflow
comment that said something close to:
JSDom has the memory leak issue since long. You should switch to Cheerio, the only issue being that it doesn’t support all the selectors
Well, yeah. It would have been better if they had just mentioned that on the Cheerio README. There was one block about supporting all sizzle selectors, but I wasn’t really sure how to check if the selectors I was using were sizzle selectors or not.
Finally, now that I had found out (the hard way) that Cheerio was not going to cut it, I moved to jsdom, and it worked well for one PNR. I was basically using jQuery and not a wrapper, so there was absolutely no issues.
Then again, integration tests failed. JSDom has had a memory leak issue for some time now, and then, they fixed the issue but dropped support for Node.js 0.12, and moved to io.js. This was absolutely frustrating for me and I had to slightly re-structure my module to take this into account.
Finally, I decided to stay with Node.js and rather, concat all the resultant HTML pieces
together and use the each function in jQuery to get all the elements matching a particular selector.
Here, again, I had to remove the one selector which had an ID with a generic selector. (ID selectors are assumed to have only one target.)
So, after about 4 hours of hacking around the code to fix everything, I spent another half-hour
doing some housekeeping stuff, proper git commits, fixing debugging lines, writing the readme,
updating the package.json file, removing unnecessary deps, etc. Once I was done with all this,
I npm version-ed it and published it to NPM.
This was my first experience working with a completely dishelved API, that had absolutely no structure to it.
So, in conclusion, JSON APIs are awesome, but even if it’s not JSON, you can get around that with a some amount of effort!